11 Best Free Online Libraries to Download Books in 2026
Public libraries built the modern world. The internet built bigger ones. In 2026 you can download a clean EPUB of Pride and Prejudice, borrow a 2024 hardcover for two weeks, listen to Moby Dick read by a volunteer in Kentucky, search across 40 million scanned titles, and read open-content textbooks on calculus and Python — all without paying for any of it. None of this requires a torrent client, a VPN, or a moral compromise. The free online libraries below are 100% legitimate, run by universities, nonprofits, and the original digital archivists who started this in the 1970s before most of us were born.
I’ve been pulling from these libraries for two decades. They’re not all good at the same things — Project Gutenberg is the canonical answer for public-domain classics, the Internet Archive is the right call for out-of-print research material, LibriVox is where audiobooks live for free, and Standard Ebooks is the under-known choice when you want the typesetting to actually be readable. Below is the breakdown of which library to use for which job, with screenshots, catalog sizes, and the part of each project that’s quietly getting better in 2026.
Affiliate disclosure: Some links to paid alternatives in this article (Kindle Unlimited, Audible) are affiliate links. The 11 free libraries below are not affiliate — they’re free public resources I use and recommend.
If you want a quick map: Project Gutenberg for classics, Open Library for borrowing modern in-copyright books, Internet Archive for out-of-print research, LibriVox for free audiobooks, Standard Ebooks for premium typesetting on the same texts Gutenberg has. Kindle Unlimited at $11.99/month is what I’d add on top if you also want bestsellers and current commercial fiction; Audible at $14.95/month covers commercial audiobooks. Both layer on top of the free libraries below — they don’t replace them.
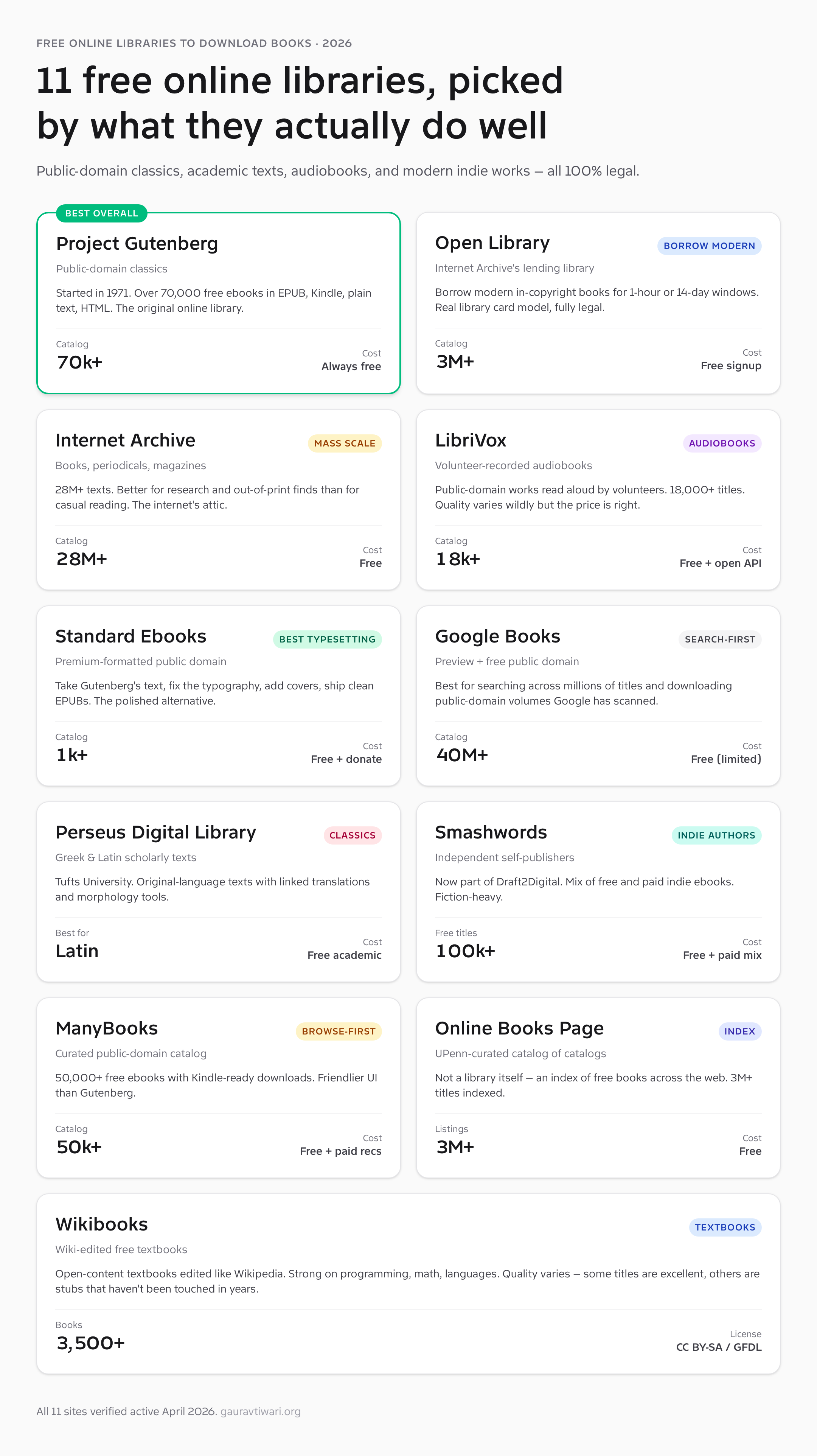
1. Project Gutenberg — the canonical free online library
Project Gutenberg started in 1971 when Michael Hart typed the Declaration of Independence into a mainframe at the University of Illinois. Fifty-five years later it’s still the canonical answer for public-domain texts on the internet. Over 70,000 free ebooks, every one in EPUB, Kindle MOBI, plain text, and HTML, and the entire catalog is available without an account, an email, or a captcha.
What’s good: The catalog depth is unmatched for anything published before 1928 (US public-domain rolling cutoff). The plain-text format makes the texts perfectly searchable and quotable in any tool. The download experience is genuinely fast — no upsell modal, no email gate, no “register to download” friction. Volunteer proofreading via Distributed Proofreaders means new public-domain works are added every week.
What’s broken: The default web design looks like it’s from 2003 because it more or less is. The typography in the EPUB files is functional but plain — these aren’t typeset books, they’re transcribed texts. If you read on a Kindle and care about chapter navigation or proper section breaks, the conversion can require manual fixing. The browse-by-genre experience is weaker than ManyBooks or Open Library.
Under the hood: Volunteer-driven nonprofit. The texts are stored as XML/HTML masters and generated to other formats on request. The full catalog is mirrored at multiple universities globally — gutenberg.org goes down occasionally and the mirrors stay up. The www.gutenberg.org/files/ URL pattern lets you script bulk downloads if you’re building a personal corpus.
What should be better: Modern typesetting. This is exactly the gap Standard Ebooks (below) was created to fill. A formal partnership where Gutenberg hosts the texts and Standard Ebooks ships the polished EPUBs would be the best of both projects.
2. Open Library — borrow modern books for free
Open Library is the Internet Archive’s lending model. They scan modern in-copyright books, lend out one digital copy at a time per physical copy they own (controlled digital lending), and you read in your browser or download a DRM-protected EPUB for the loan period. Free signup, free borrowing, fully legal under the same first-sale doctrine that lets your local library lend you the same book.
What’s good: Modern catalog. This is where you find books published in the last 30 years that aren’t on Gutenberg. 1-hour and 14-day loans give you flexibility — quick lookups don’t need the full two weeks. The “Want to Read” / “Currently Reading” / “Already Read” lists work like Goodreads for personal tracking, but without Goodreads’ Amazon ownership.
What’s broken: The legal pressure on controlled digital lending is real. The Hachette v. Internet Archive ruling (2023, upheld 2024) limited what they can lend, and some titles that used to be available no longer are. Wait queues for popular books can be weeks long. The reader app is fine for short sessions, less great for marathon reading on a phone.
Under the hood: Built on the Internet Archive’s existing scan infrastructure. Every borrowable book corresponds to a physical book the Archive owns, sitting in their warehouse in Richmond, California. The lending DRM uses Adobe Digital Editions for downloads or in-browser reading via the BookReader project (open-source).
What should be better: Resilience to legal challenges. The CDL model is genuinely under threat and the project deserves a more secure footing. Donating helps — they’re a 501(c)(3).
3. Internet Archive — the research library
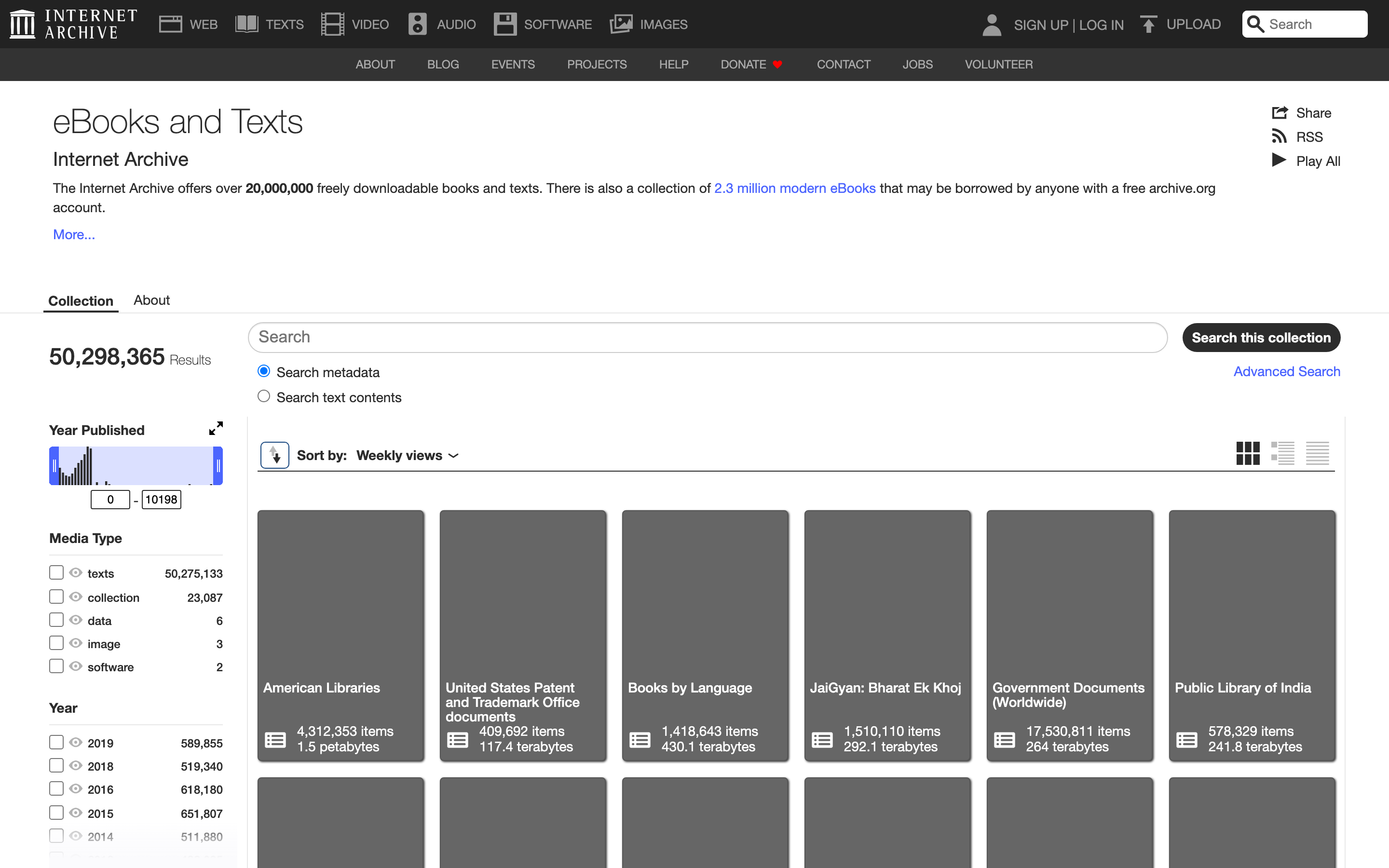
Internet Archive hosts 28 million+ digitized texts including books, magazines, journals, government documents, and obscure technical manuals nobody else preserved. If you’re researching the history of anything, this is the first place to look — out-of-print 1950s engineering textbooks, defunct magazine archives, declassified reports, and university press monographs that never went digital anywhere else.
What’s good: Breadth. The catalog goes places no other library does — back issues of BYTE Magazine, original NASA technical reports, every Mad Magazine published before 2000, the personal book collection of MIT’s Marvin Minsky. Full-text search across the entire corpus actually works at this scale, which is its own minor miracle.
What’s broken: Quality varies wildly. Some scans are pristine; others were photographed at 90 dpi by a volunteer in 2007 and are barely legible. The OCR layer is similarly hit-or-miss — older Gothic typefaces and bilingual texts often have substantial recognition errors. Browse navigation is overwhelming because the catalog is.
Under the hood: Custom scanning rigs (the “Scribe” stations) that flip and photograph pages at scale. Storage is on the Archive’s own infrastructure — multi-petabyte arrays in Richmond, California with mirror sites globally. Full-text indexing via Elasticsearch. The archive.org API lets you script downloads, search, and metadata queries without rate limiting for reasonable use.
What should be better: Scan quality consistency. A modern rescan program for the worst pre-2010 scans would make a measurable difference. The project knows this — they’ve prioritized breadth over polish historically because the alternative is items disappear forever.
4. LibriVox — free public-domain audiobooks
LibriVox is what happens when 19,000 volunteers spend twenty years recording themselves reading public-domain books aloud. Over 18,000 finished audiobooks, every one free, downloadable as MP3 or M4B, with no signup required. If you want War and Peace as an audiobook for free, this is the only legal option that actually exists.
What’s good: The catalog covers titles Audible doesn’t bother with. Foreign-language recordings of works in the original. Multiple narrations of the same book by different volunteers, so you can pick the voice you actually want to spend 40 hours with. The open API and bulk-download options make it trivial to load up an iPod (or a Plex audiobook server) with thousands of hours of material in one afternoon.
What’s broken: Quality variance is the project’s defining feature. Some volunteers are professional voice actors; some are reading into a built-in MacBook microphone with the heating system humming in the background. The recording quality of older entries (2005-2010) is markedly worse than recent ones. Listen to a 5-minute sample before committing.
Under the hood: Hosted by the Internet Archive (audio files live in archive.org). Volunteer coordination via the LibriVox forum, with proofreading and quality-checking by experienced readers. Each chapter is recorded by one volunteer; multi-voice “dramatic readings” coordinate cast members across continents.
What should be better: A modern web player. The site UI is functional but the listen-in-browser experience hasn’t been touched in a decade. A LibriVox iOS/Android app would make the catalog far more accessible than the current “find the M4B, sideload it” workflow.
5. Standard Ebooks — premium typesetting for free

Standard Ebooks is the under-known answer to “Project Gutenberg’s typography is bad.” Volunteers take Gutenberg’s plain-text masters, apply consistent CSS typography, hand-correct OCR errors, design original public-domain covers, and ship genuinely premium-quality EPUBs. The catalog is around 1,000 titles in 2026, smaller than Gutenberg, but every one is the version you’d actually want to read.
What’s good: The typography is on par with paid ebook stores — proper drop caps, smart quotes, clean section breaks, modern font pairings. Cover designs are commissioned individually rather than auto-generated. Every title goes through proofreading and stylistic review before release. If you’re a Kindle reader who’s ever winced at a Gutenberg conversion, Standard Ebooks is the upgrade.
What’s broken: Catalog size. 1,000 titles is genuinely small compared to the alternatives. The release cadence is steady but slow because each book takes weeks of volunteer effort. Don’t expect to find every classic — focus is on titles where the typesetting effort makes the most difference.
Under the hood: All texts are in a public GitHub repository. The toolchain (semantic HTML, custom CSS, an SE-Build CLI) is open-source and well-documented. Anyone can submit a new title or improvements to an existing one. The project funds itself via donations rather than selling anything.
What should be better: More volunteers. The project’s biggest constraint is contributor capacity. If you’ve ever wanted to learn EPUB internals while doing genuinely useful work, Standard Ebooks is the place.
6. Google Books — search-first free library
Google Books is the world’s biggest book search engine wearing a library coat. Google scanned ~40 million titles between 2004 and 2016 and the corpus has been searchable ever since. For most in-copyright books you get a snippet view; for public-domain works you can read or download the full PDF.
What’s good: Search across 40 million titles is the killer feature. Need to find every book that mentions “Aryabhata’s contribution to trigonometry”? Google Books will find them, with the relevant pages highlighted. For research, this beats every other library on this list combined. The “Read this book online” download for public-domain titles produces clean PDFs with readable OCR.
What’s broken: The interface hasn’t been updated meaningfully since 2014. Google effectively abandoned the project after the Authors Guild lawsuit settled, so there’s no active development — just maintenance. Many in-copyright books that used to show full preview are now snippet-only because publishers requested it. The download formats for public-domain titles are PDF only (no EPUB).
Under the hood: Custom scanning rigs that automated page-flipping at libraries (Stanford, Harvard, Oxford, Michigan, NYC Public). Full-text OCR with Google’s own engine. The corpus is also part of the Google Ngram Viewer, which is independently fascinating for word-frequency research over centuries.
What should be better: Modernization. Active development would let Google Books be a great library; right now it’s a great search engine pretending to be one. The product feels like it’s running on cruise control.
7. Perseus Digital Library — classics scholarship
Perseus Digital Library at Tufts University is the place for Greek and Latin scholarship. Original-language texts of Homer, Cicero, Plato, and Virgil with linked English translations, morphology tools that parse every word, and cross-references to scholarly commentary. If you’re studying classics or just want to read The Iliad with the Greek line-by-line, Perseus is unmatched.
What’s good: The morphology tool is the killer feature — click any Greek or Latin word and Perseus tells you the dictionary form, the grammatical case, and a link to the LSJ or Lewis & Short entry. For independent learners working through original texts, this is closer to having a tutor than any other free resource. The English translations are paired tightly to the source.
What’s broken: The interface is academically focused, which is polite for “looks like a 2008 university website.” Mobile experience is poor. Downloading texts in standard ebook formats requires going through individual chapter pages.
Under the hood: XML/TEI-encoded texts (the academic standard for digital humanities), morphology powered by the Smyth Greek grammar and Allen & Greenough’s Latin grammar. The codebase is open-source and the data is licensed for reuse — multiple downstream projects (Scaife Viewer, Logeion) build on the same corpus.
What should be better: A modern reader interface. Perseus Catalog (the newer Scaife Viewer) is gradually replacing the original Hopper interface and looks substantially better. Worth using when available.
8. Smashwords — indie authors, mostly free
Smashwords is the largest distributor of indie self-published ebooks. Now part of Draft2Digital after the 2022 merger, the catalog has 100,000+ titles available for free, plus hundreds of thousands more for sale. Fiction is the dominant genre — indie romance, sci-fi, fantasy, thrillers — but there’s also strong representation in business and personal-development self-publishing.
What’s good: Strong free-tier strategy. Many indie authors offer the first book in a series free as a hook, so you can sample widely without risk. Multiple format downloads per title (EPUB, MOBI, PDF, HTML, plain text). Author profiles with sample chapters.
What’s broken: Discoverability. With 700,000+ titles and genuinely uneven quality, finding the gems requires patience. The site search is okay but not great. The interface still looks like 2010s ebook stores.
Under the hood: Owned by Draft2Digital since 2022. Distribution model means the same titles often appear on Amazon, Apple Books, and Barnes & Noble — Smashwords is the consolidator, not always the publisher.
What should be better: Curation. Editorial picks, “if you liked X you’ll like Y” recommendations, and genre deep-dives would help readers find good books faster.
9. ManyBooks — the friendly Gutenberg frontend
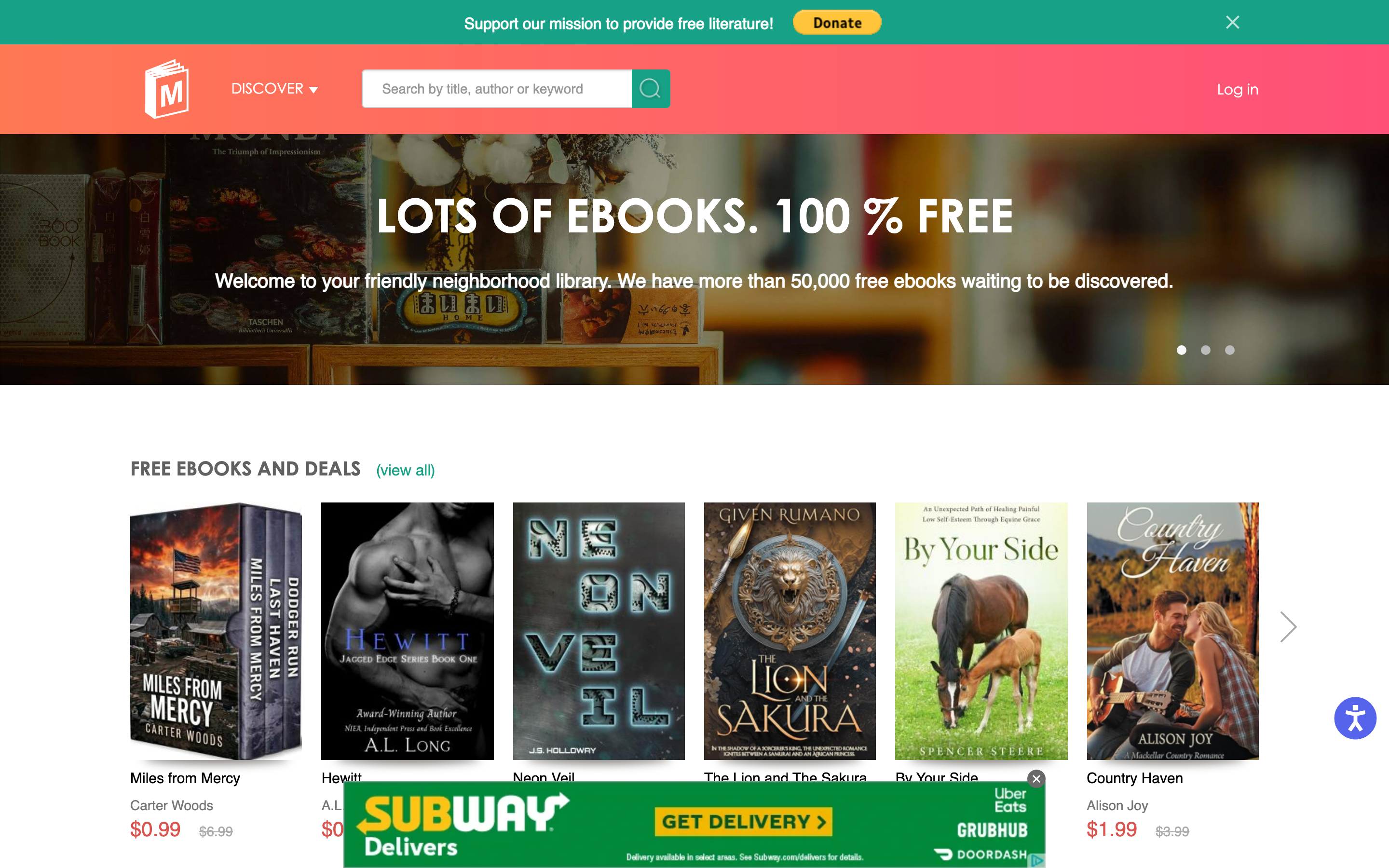
ManyBooks is what Project Gutenberg would look like if it had a designer. Same ~50,000 public-domain titles, but presented with covers, genre browsing, ratings, descriptions, and Kindle-ready downloads. If you find Gutenberg’s interface too utilitarian, ManyBooks gets you to the same texts via a friendlier path.
What’s good: Genre browsing actually works. Cover thumbnails, descriptions, and ratings make discovery much more like a real bookstore. Kindle-direct send is convenient. Works as a starting point for readers new to public-domain ebooks who don’t want to navigate Gutenberg’s text-only catalog.
What’s broken: Mixed in with the free public-domain catalog are paid ebook recommendations and affiliate links to Amazon. The site monetizes via these recommendations, which is fair, but the labeling could be clearer about which downloads are free and which require purchase.
Under the hood: ManyBooks pulls public-domain texts primarily from Gutenberg and adds metadata, covers, and a friendlier UI on top. The downloads are the same EPUB/MOBI files Gutenberg produces, with format conversion done at delivery time.
What should be better: Clearer free vs paid labeling. The mixed catalog confuses first-time visitors who expected an entirely-free library.
10. The Online Books Page — the catalog of catalogs

The Online Books Page at the University of Pennsylvania is meta-library — it’s not a library itself, but a curated index of free books across the entire web. Over 3 million titles indexed across hundreds of source sites. If a public-domain or open-access book exists online and is legitimate, this site will tell you where to find it.
What’s good: Curation by a real librarian (John Mark Ockerbloom, who’s been maintaining it since 1993) means the index is selective rather than scraped. Every linked source is checked for legality and persistence. The “New listings” page is a useful weekly feed for anyone tracking what’s newly entered the public domain.
What’s broken: Looks like a 1995 university homepage, which it more or less is. Search is functional but basic. Browse is by Library of Congress classification, which is academically correct but unfamiliar to most readers.
Under the hood: Hand-curated index (literally — the maintainer reviews submissions). Static HTML pages generated from a database. The infrastructure is intentionally simple because the site is intended to outlast trendy CMSes.
What should be better: A modern frontend would dramatically expand the audience. The underlying catalog is genuinely valuable; the presentation buries it.
11. Wikibooks — free open-content textbooks
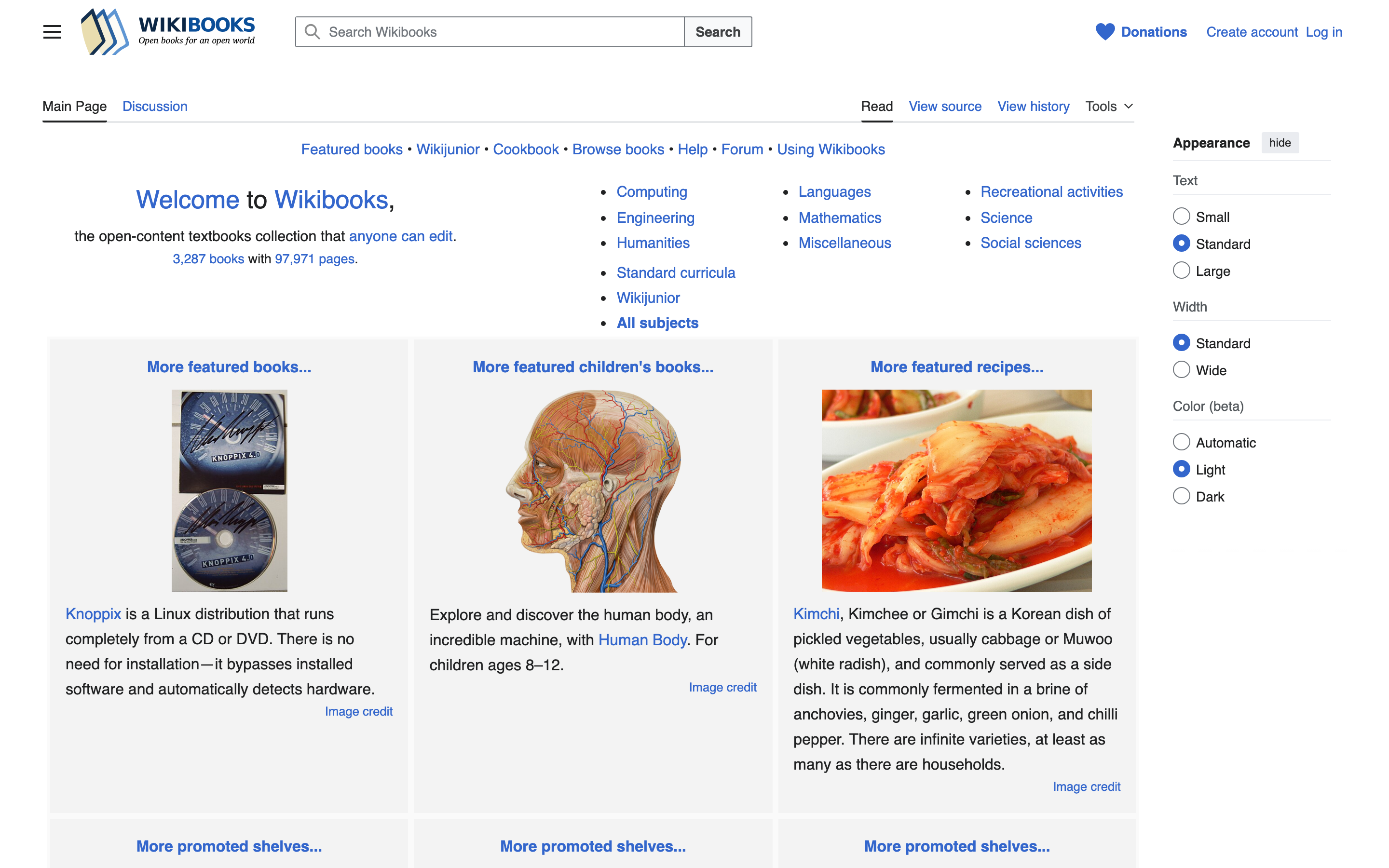
Wikibooks is the Wikimedia Foundation’s textbook project — open-content learning materials edited collaboratively like Wikipedia. 3,500+ books in 2026, strongest in programming languages, mathematics, language learning, and free software documentation. Quality varies but the best titles are competitive with paid textbooks.
What’s good: The “Featured Books” list highlights the genuinely good titles. Programming books on languages like Haskell, Lua, and Erlang are surprisingly thorough. Math textbooks (linear algebra, calculus, abstract algebra) cover the standard undergraduate curriculum. Print-friendly export to PDF works for offline reading.
What’s broken: Stub problem. Wikibooks has thousands of incomplete books that haven’t been touched in years. Many “books” are essentially outlines with placeholder chapters. The featured-books filter is essential — random browsing produces too many half-finished titles.
Under the hood: Same MediaWiki engine as Wikipedia. Content is dual-licensed under CC BY-SA and the GFDL. Anyone can edit, with the same revision-history and discussion-page infrastructure as Wikipedia. PDF export uses the Wikimedia rendering service.
What should be better: Editorial pruning. The project would benefit from archiving truly stalled books rather than letting them clutter searches indefinitely. The featured-content workflow is the model — it just needs to apply more aggressively.
Free online libraries: catalog and use case at a glance
| Library | Best for | Catalog size | Format | Account needed |
|---|---|---|---|---|
| Project Gutenberg | Public-domain classics | 70,000+ | EPUB/MOBI/TXT | No |
| Open Library | Borrowing modern books | 3M+ borrowable | In-browser/EPUB | Yes (free) |
| Internet Archive | Out-of-print research | 28M+ | PDF/EPUB/streaming | No (some borrow needs) |
| LibriVox | Free audiobooks | 18,000+ | MP3/M4B | No |
| Standard Ebooks | Premium typesetting | 1,000+ | EPUB | No |
| Google Books | Search across millions | 40M+ | PDF (public domain) | Optional |
| Perseus | Greek & Latin classics | ~1,000 texts | HTML + XML | No |
| Smashwords | Indie ebooks | 700k+ (100k free) | EPUB/MOBI/PDF | Optional |
| ManyBooks | Browsable Gutenberg | 50,000+ | EPUB/MOBI/Kindle send | No |
| Online Books Page | Index of indexes | 3M+ listed | Links only | No |
| Wikibooks | Open-content textbooks | 3,500+ | HTML/PDF | No |
When the free libraries aren’t enough: legitimate paid add-ons
The free libraries above cover public-domain works (anything published before 1928 in the US) and indie self-published material. They don’t cover commercial bestsellers, current literary fiction, most contemporary nonfiction, or the audiobook narrations that Hollywood-grade voice actors do. For those, you need paid services. The two I’d actually recommend layering on top:
- Kindle Unlimited ($11.99/month): 4M+ titles from current commercial fiction and nonfiction. The catalog is Kindle-only and rotates over time, but for genre fiction (sci-fi, romance, thrillers) the value is real. Free 30-day trial. See my full Kindle Unlimited review for whether it’s worth subscribing in 2026.
- Audible ($14.95/month): Where commercial audiobook production lives. Multi-narrator dramatizations, celebrity-narrated bestsellers, exclusive Audible Originals. One credit per month plus access to the Audible Plus catalog. LibriVox is for the classics; Audible is for everything else.
For physical books on a budget, your local public library is still the best option in 2026. Most US public libraries have Libby (formerly OverDrive) integration for digital lending — free with a library card, modern catalog, no subscription. If you don’t have a library card yet, signing up is free and takes 15 minutes; this is the most underused free resource in America.
The hardware that makes free libraries actually usable
Downloading 40 free epubs means nothing if you end up reading them on a phone screen at 11 pm. An e-ink reader is the difference between hoarding free books and finishing them. Every library on this list exports epub, and getting those files onto a Kindle Paperwhite takes one drag-and-drop through Amazon’s free Send to Kindle tool. The entry-level basic Kindle at $109.99 handles the same job if you read in decent light. Kobo readers go one step further for library users: Libby/OverDrive borrowing is built into the device, no sideloading needed. I compared the current models in my best e-readers guide.

Amazon Kindle Paperwhite 16GB (12th Generation)
- Reads every epub from Gutenberg, Standard Ebooks, and ManyBooks via free Send to Kindle
- 7-inch glare-free e-ink display that works in direct sunlight
- 16GB holds roughly 10,000 public-domain ebooks — more than you will ever read
- Up to 12 weeks of battery on one USB-C charge
What I’d actually use in 2026
If I’m reading classic literature on a Kindle, Standard Ebooks first (better typography), Project Gutenberg as fallback (broader catalog). If I’m researching anything historical, the Internet Archive is the first stop — full-text search across 28M items finds material that doesn’t exist anywhere else. For modern in-copyright books I want to read but not own, Open Library’s lending model. For audiobooks, LibriVox for classics and Audible for current commercial titles.
Most readers should set up exactly two accounts: one at Open Library for digital lending, one at their local public library for Libby. That covers ~95% of what most people actually want to read, and both are free. Add Kindle Unlimited or Audible only if you’ve maxed out the free options and find yourself still buying books on Amazon.
For deeper reading, see my notes on how to highlight while reading and reading statistics that matter. If you’re book-shopping by genre, my programmer reading list, Python beginner books, and cryptography reading list point at specific titles worth pulling from these libraries first.
Are these free online libraries legal to download from?
u003cpu003eYes. Every library in this article distributes either public-domain works (where copyright has expired), open-content works (Creative Commons or similar licenses), or operates under controlled digital lending (one digital copy per physical copy owned). None of them are piracy sites. Project Gutenberg, the Internet Archive, LibriVox, Standard Ebooks, and Wikibooks are all 501(c)(3) nonprofits or university-hosted projects.u003c/pu003e
Which is the best free online library to download books?
u003cpu003eProject Gutenberg is the canonical pick for public-domain classics — 70,000+ titles in EPUB, Kindle, and plain text, no signup required. For modern in-copyright books, Open Library’s lending model is the legal answer. For audiobooks, LibriVox. For premium typesetting on classics, Standard Ebooks. The right answer depends on what you’re trying to read.u003c/pu003e
Can I download free books to my Kindle?
u003cpu003eYes. Project Gutenberg, Standard Ebooks, ManyBooks, and Smashwords all offer Kindle-compatible MOBI or EPUB downloads. Send-to-Kindle by email is the simplest method: enable it in your Amazon account, then email the EPUB file to your Kindle address. Some libraries (ManyBooks, Open Library) offer one-click Kindle delivery directly.u003c/pu003e
Are free online libraries safe?
u003cpu003eThe 11 libraries in this article are run by universities, nonprofits, or established projects with multi-decade track records. Downloads from these sites are safe — no malware, no trackers, no requirement to install software. If a free library site asks you to install a custom downloader or disable antivirus to access content, it is not legitimate. Every library here delivers files via standard browser downloads.u003c/pu003e
What is the largest free online library?
u003cpu003eThe Internet Archive’s text collection is the largest single free library, with 28 million+ digitized books, periodicals, and documents. Google Books indexes 40M+ titles but only allows full download for public-domain works. The Online Books Page indexes 3M+ free book listings curated from sources across the web.u003c/pu003e
Where can I find free audiobooks online legally?
u003cpu003eLibriVox is the canonical free audiobook library — 18,000+ public-domain audiobooks recorded by volunteers, free MP3 and M4B downloads, no signup. The Internet Archive also hosts free audiobook collections. For commercial audiobooks, Audible’s $14.95/month subscription is the legitimate paid option, and most US public libraries offer free audiobook lending via the Libby app.u003c/pu003e
Why are some books missing from these free libraries?
u003cpu003eCopyright. Most books published in the US after 1928 are still in copyright, which means they cannot legally be distributed for free without the rights-holder’s permission. The free libraries in this article focus on public-domain works (copyright expired) and open-content works (Creative Commons). For in-copyright books, Open Library’s lending model and your local public library are the legal free options.u003c/pu003e
Do I need an account to use these free libraries?
u003cpu003eMost don’t require an account. Project Gutenberg, Standard Ebooks, LibriVox, Internet Archive (for non-borrow content), Wikibooks, Perseus, the Online Books Page, and ManyBooks all let you download without signing up. Open Library requires a free account to borrow modern books (since they enforce loan limits). Smashwords is optional. Google Books works without an account but personalizes results when you sign in.u003c/pu003e
Disclaimer: This site is reader-supported. If you buy through some links, I may earn a small commission at no extra cost to you. I only recommend tools I trust and would use myself. Your support helps keep gauravtiwari.org free and focused on real-world advice. Thanks. - Gaurav Tiwari
I WANT A SOFT COPY OF DR. GODWIN DZOKOTO BOOK ON THE LAW OF MORTAGAGES IN GHANA